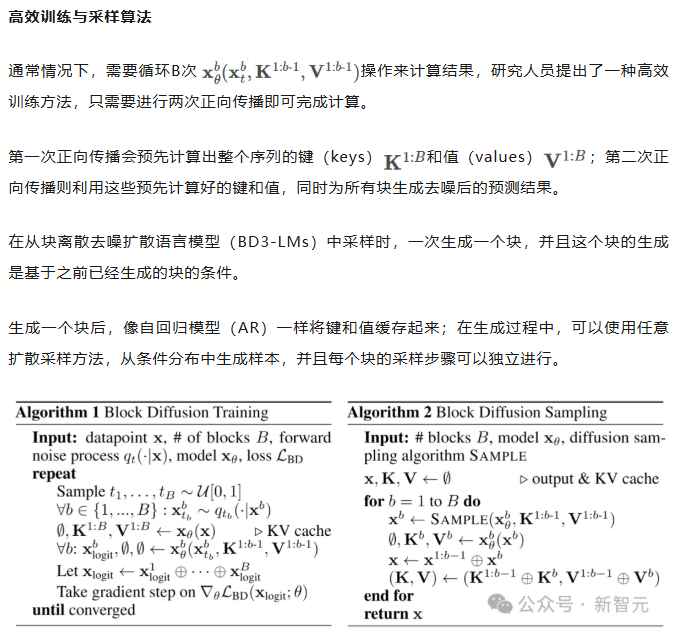
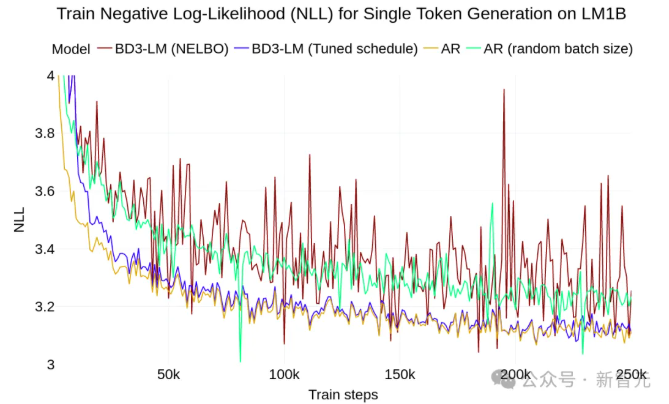
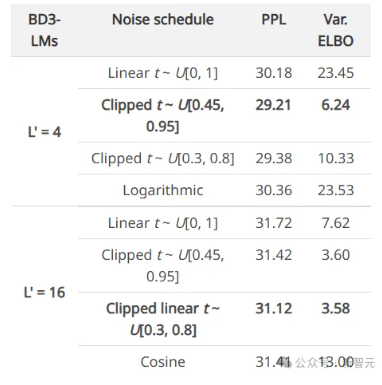
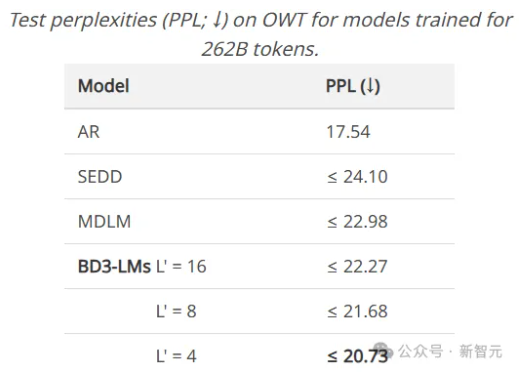
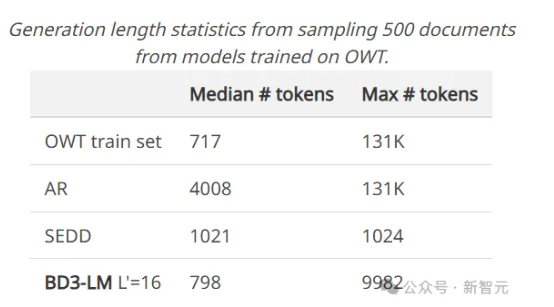
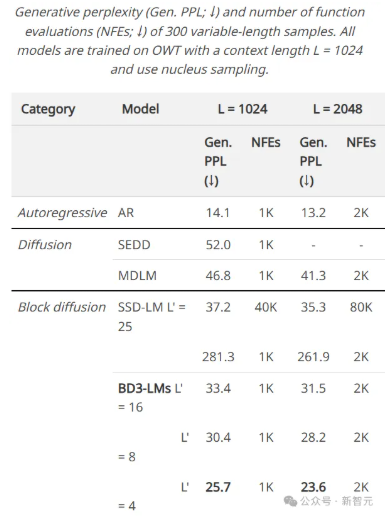
论文精读Block Diffusion:Interpolating Between Autoregressive and Diffusion Language Models 酥酥 发布于 2025-04-19 89 次阅读 块离散去噪扩散语言模型(BD3-LMs)结合自回归模型和扩散模型的优势,解决了现有扩散模型生成长度受限、推理效率低和生成质量低的问题。通过块状扩散实现任意长度生成,利用键值缓存提升效率,并通过优化噪声调度降低训练方差,达到扩散模型中最高的预测准确性,同时生成效率和质量优于其他扩散模型。 扩散模型被广泛应用于生成图像和视频,并且在生成离散数据(如文本或生物序列)任务上的效果也越来越好,与自回归模型相比,扩散模型有望加速「生成过程」并提高模型输出的「可控性」。然而,离散扩散模型目前仍然有三个局限性: 在聊天系统等应用中,模型需要生成任意长度的输出序列(例如,对用户问题的回答),但大多数现有的扩散架构只能生成固定长度的向量; 离散扩散在生成过程中使用双向上下文,因此无法利用键值缓存(KV caching)复用之前的计算,使得推理效率较低。 从困惑度等标准指标来看,离散扩散模型的质量仍落后于自回归方法,也进一步限制了其应用范围。 为了克服这些局限性,康奈尔科技校区(Cornell Tech)、斯坦福大学的研究人员提出了「块离散去噪扩散语言模型」(BD3-LMs,Block Discrete Denoising Diffusion Language Models),介于离散扩散模型和自回归模型之间:块扩散模型(也称为半自回归模型)在离散随机变量的块上定义了一个自回归概率分布;给定前面的块,当前块的条件概率由离散去噪扩散模型指定。 论文链接:https://arxiv.org/pdf/2503.09573 代码链接:https://github.com/kuleshov-group/bd3lms 想要开发出一个高效的BD3-LMs,仍然有两大难题需要解决: 计算块扩散模型的训练目标无法通过神经网络的标准前向传播实现,需要开发专门的算法; 扩散目标的梯度方差较大,导致即使在块大小为1(此时两种模型理论上等价)时,BD3-LMs的表现仍不如自回归模型。 研究人员通过推导梯度方差的估计器,发现了导致自回归模型与扩散模型之间困惑度差距的关键因素,文中提出了定制的噪声过程,以最小化梯度方差,并缩小了困惑度差距。 研究人员在语言建模基准测试中评估了BD3-LMs,结果表明,该模型能够生成任意长度的序列,包括超出其训练上下文长度的序列,并且在离散扩散模型中达到了新的最低困惑度。 与在嵌入层上进行高斯扩散的其他半自回归方法相比,文中提出的离散方法具有可处理的(tractable)似然估计,并且在生成步骤少了一个数量级的情况下,生成样本的困惑度还更低。 Block Diffusion语言建模 自回归语言模型vs扩散语言模型 BD3-LMs 研究人员结合了自回归模型在「生成质量」和「灵活长度生成」方面的优势,以及扩散模型在「快速并行生成」方面的优点,提出了块离散去噪扩散语言模型(Block Discrete Denoising Diffusion Language Models,BD3-LMs)。 块扩散似然 研究人员提出了一种新的建模框架,将token分组成块(block),并在每个块内执行扩散操作。 具体来说,模型以自回归的方式处理这些块,同时在每个块内部使用扩散模型进行生成,其似然函数可以分解为B个长度为L’的部分。 扩散模型与自回归模型之间的似然差距 单个token生成 块扩散模型在理论上与自回归模型的负对数似然(NLL)是等价的,尤其是在L’=1的极限情况下。 然而,研究人员发现,在LM1B数据集上训练这两种模型时,即使在块大小为1的情况下,块扩散模型与自回归模型之间仍然存在2个点的困惑度差距。 经过分析,可以发现扩散模型的目标函数在训练过程中具有较高的方差,是导致困惑度差距的主要原因。 在离散扩散模型的训练中,使用变分下界(ELBO)时会遇到高方差的问题。 从直觉上来说,如果被遮蔽的部分太少,那么恢复原始内容就会很容易,这种情况下模型就得不到有效的学习信号; 反过来,如果把所有内容都遮蔽掉,那么最优的恢复方式就是简单地根据数据分布中每个token的独立概率来进行猜测,这种任务虽然容易完成,但也同样没有意义。 最终的目标是找到一种合适的噪声调度(noise schedule),以减少由扩散目标引起的训练过程中的波动,并进一步缩小模型在困惑度上的差距。 为了避免因遮蔽率(masking rates)过高而导致训练过程中的大幅波动,研究人员在训练块离散去噪扩散语言模型(BD3-LMs)时,采用了「限制性」的遮蔽率:通过降低训练过程中的波动,当在评估时使用均匀采样的遮蔽率时,模型的预测准确性得到了提升。 由于最优的遮蔽率可能因块的大小而有所不同,研究人员在训练过程中自适应地学习这些遮蔽率,在每次验证步骤中,每完成5000次梯度更新后,通过网格搜索来优化遮蔽率。 研究结果表明,针对每个块大小优化噪声调度可以减少损失估计器的方差,并在与其他噪声时间表的比较中实现最佳的困惑度性能。 实验结果 似然评估 BD3-LMs在扩散模型中达到了最先进的预测准确性(似然性),通过调整块的长度,BD3-LMs能够在扩散模型的似然性和自回归模型的似然性之间实现平衡。 任意长度序列生成 许多现有的扩散语言模型有一个重大缺陷:无法生成比训练时选择的输出上下文长度更长的完整文档。 例如,OpenWebText数据集中包含的文档最长可达13.1万个tokens,但离散扩散模型SEDD只能生成最多1024个token的内容。 实验结果展现了BD3-LMs能够通过解码任意数量的块来生成长度可变的文档,研究人员评估了BD3-LMs在生成长度可变的序列时的质量,并使用相同的生成步数(NFEs)来比较所有方法。 研究人员还测量了在GPT2-Large模型下采样序列的生成困惑度,结果显示BD3-LMs在所有之前的扩散方法中达到了最佳的生成困惑度。 研究人员还将其与半自回归SSD-LM进行了比较,在词嵌入上执行高斯扩散,但无法进行似然估计;相比之下,文中提出的离散方法在少一个数量级的生成步数下,生成的样本具有更低的生成困惑度。 简单来说,BD3-LMs不仅能够生成任意长度的文档,而且在生成效率和质量上都优于其他扩散模型。 https://arxiv.org/pdf/2503.09573 —文章来源 新智元













Comments NOTHING