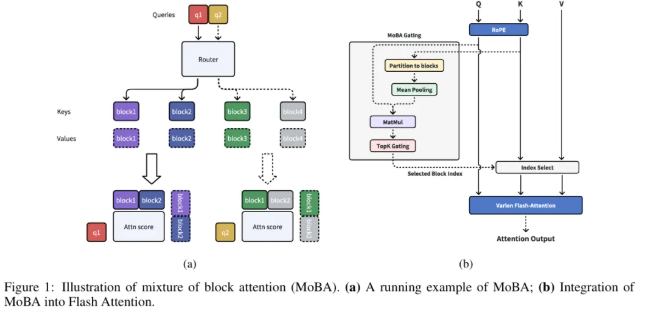
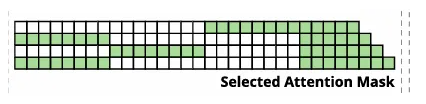
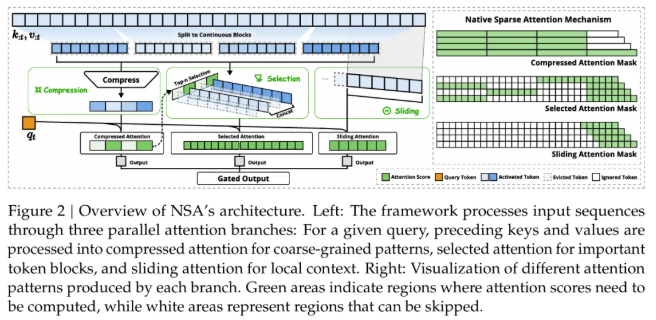
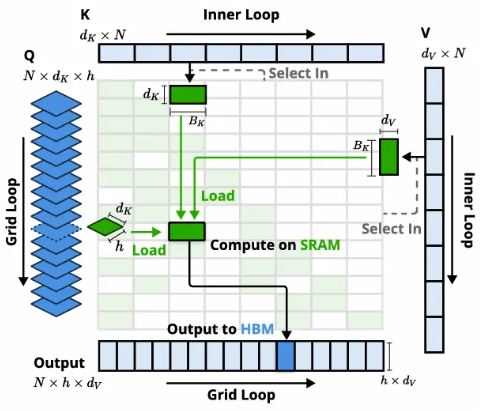
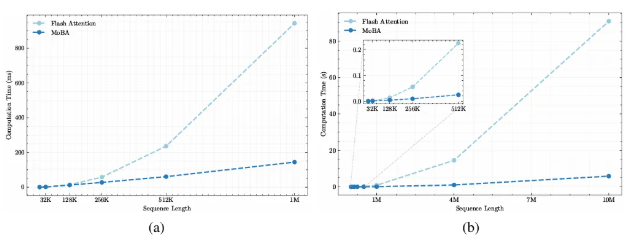
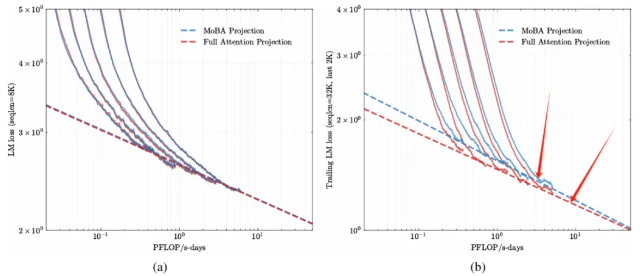
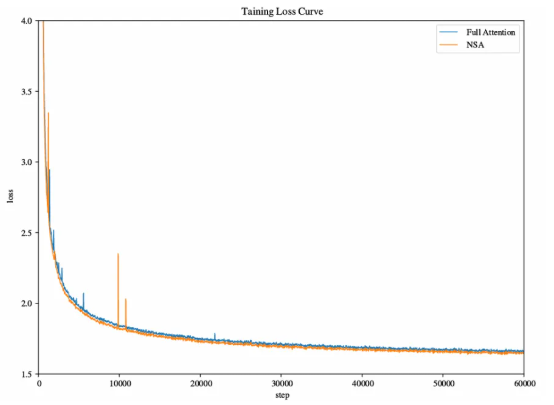
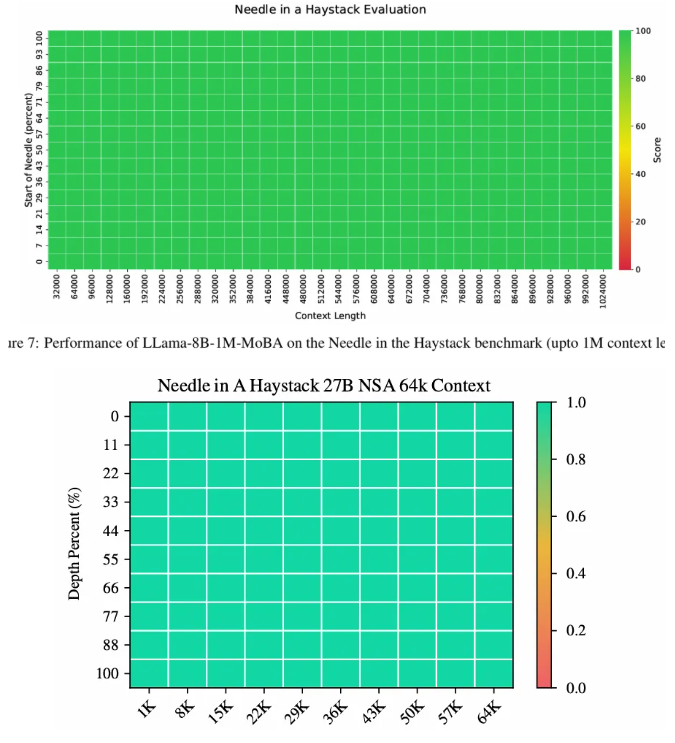
一文比较 Kimi 和 deepseek 的两篇稀疏注意力机制论文 酥酥 发布于 2025-02-24 79 次阅读 就在昨天,Kimi 和 Deepseek 分别发布了一篇论文,发布时间和论文主题内容都高度相似。我第一时间把两篇论文阅读完了,急忙跑来写写我对这两篇论文的感想和体会。如果简单概括总结的话,两篇论文那就是:高手过招,神仙打架,你中有我,我中有你,让我身在国内感受到了 AI 科技进步的点滴。话不多说,我先说一下两篇论文各自的内容,然后做一番比较。两篇论文要解决的问题Transformer 这个老模型大放异彩自不必说,但是计算量还是偏大,尤其是现在长上下文建模,模型的长度动不动就往8k、32k、128k飙,对于 GPU 压力太大。而 Transformer 的核心注意力机制就是针对每一个 q,要去匹配整个上下文长度所有的 k 和 v,来做计算,这样的遍历计算量非常大,所以,Kimi 和 Deepseek 两篇论文都是想解决这样的问题,针对每一个q,只碰撞一部分 k 和 v,节约计算资源,也就是 Sparse Attention,稀疏注意力机制。 Kimi 的论文核心点Kimi 的论文叫做《MoBA:MIXTURE OF BLOCK ATTENTION FOR LONG-CONTEXT LLMS》,话说我看到 MoBA,就很容易想起来 5V5 手游。。。MoBA 方法的解决思路是,既然只想让 q 去匹配一部分 k 和 v,那么就先给整个序列长度的位置划分为许多个相同大小的 block,先去匹配计算 q 和哪些 block 更加相关,抛弃哪些不怎么相关的信息。 具体让 q 和哪些 block 碰撞呢?首先,要和 q 当前位置所在的 block 做碰撞,这相当于是 q 要和自己紧邻最近的上下文的内容做一次关联。这非常符合直觉,与自己最相近的信息关联度最大。然后,就是要让 q 和剩余的每一个 block 做一次相关度关联,把那些相关度高的找出来,丢弃相关度底的。具体操作就是让每一个 block 都做一遍 mean pooling,然后让 q 和这个 mean pooling 做内积,就会得到一个关联度值,写成公式就是下面这样。我是用语言表述哈。 我用语言还是抽象了,画成下面的图更清楚。这张图中绿色就是被选中要和 q 碰撞的 kv 位置。最右侧就是 q 所在的当前 block。最有意思的地方来了,这张图是 Deepseek 论文里画的图,它形象展现了 Kimi 论文里的内容。这就是我文章开头说的,你中有我,我中有你。 当然,每一个当前 block,还是会有一些位置 超前于当前的 q 位置,对于自回归模型,这些是需要被 mask 掉的,这部分在图中也被清晰的用右侧阶梯形状表示出来了。这样一来,Attention 注意力机制就被稀疏化了。这里还有一点,具体从备选 block 里面选哪几个?有数量限定,这是模型超参数。如果全选,那就是 Full Attention,如果一个都不选呢?那就是 Sliding Window Attention,滑动窗口 Attention。总而言之, MoBA 实际上是把若干种 Sparse Attention 做了一次归纳和泛化。最根本的目的,是希望提出一种一般化的,general 的 Sparse Attention 方法。 MoBA 的目的,是把 Sparse 这个过程给一统江湖了,以后再有什么论文提出别的千奇百怪,花里胡哨的 Sparse 方法,MoBA 拍拍新论文肩膀:“别折腾了,兄弟,都是我玩剩下的。。。”好了,我们再看 Deepseek 的操作。Deepseek 的论文核心点Deepseek论文名字叫《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》,简称 NSA。这篇论文为了把注意力机制搞稀疏,也是先把整个文本序列先搞成若干 block,然后再做各种操作。除了上面 Kimi 提到的 block selection 方法,还加了另外两种方法。 一种是找出一种粗粒度的被压缩过的 k 和 v,也就是图中左图的左侧,右图的最上方,它起名叫 Compressed Block Attention。这种压缩信息,粒度比较粗,论文中写作 coarse granularity。它实际上就是把若干个 block,用 MLP 压缩一下,拼接起来,形成一个短小的 k 和 v,去和对应的 q 做碰撞。文中公式是这样。 还需要说明的是,这样粗粒度对每一个 block 做的操作,实际上可以得到一组关联度值,还记得 Kimi 那里讲到的需要给每一个 block 附一个相关性值吗?在 Deepseek 这里,这个值如果划分 block 的大小都是固定的话,直接就从 coarse attention 这里薅过来为 selection attention 所使用了。还有第三种方法,Sliding window 方法,哎,前面不是已经提过了么?就是 Kimi 论文中已经描述过的,Sliding window 方法就是 Block selection 方法的一种特殊形式。从图中的三种方法的 Mask 就能看出来。说白了,两篇论文真的做到了你中有我,我中有你。当然,两种方法还有一点细微的差别,那就是 NSA 中的滑动窗口,是会跨 block 的。三种 Sparse 策略,三管齐下,得到的所有 q 和 kv 碰撞计算的结果,全部 concat 在一起,作为输出。公式写成这个样子: 当然,Deepseek 还基于 Triton 对硬件加速 qkv 操作做了详细的阐述:这幅图展示了在存储上,是如何操作注意力机制的。 两篇论文的数据比较先比较计算耗时Kimi 是这样的 Deepseek 是这样的: 两者都展现了 Sparse Attention 的优越性,都是在和 Flash Attention 作比较,都比 Flash Attention 快得多。实验上各有优劣。Kimi 尝试的长度达到了 100万,而 Deepseek 则是分前向传播和反向传播做了对比试验。再比较模型效果先说 Kimi,既然只选取了部分关联度高的 block 来做注意力计算,那么肯定就丢失了一部分信息,即便那部分信息量再少,肯定多少还是丢失了,会对最终结果有影响,效果如图所示:可以看出蓝色 MoBA 线比红色线高一些,代表损失值更高。不过,随着训练加深,蓝色线再逐渐逼近红色线。这说明理论上 Kimi 的 block selection 方法是可以达到理论最佳,追上 full attention 的。 Deepseek 则更加粗暴:我效果就是比 full attention 强。如下图所示(PS,这论文里 training 怎么还拼成 taining 了?应该拿 R1 让 AI 做一遍 proof 的哈) 这里,Deepseek 的 NSA 方法损失值比 full attention 还略微低了一丢丢。从这里两篇论文的比较来看,Kimi 的 MoBA 只采用了一种 block selection 的方法,而 NSA 则融合了三种方法,可以说明,NSA 附加的另外两种产生了一定的效果。好了,讨论到了两篇文章实验效果环节,那就是,一个比 full attention 强一丢丢,一个比 full attention 弱一丢丢,那到底差多少呢?有对比实验 needle in a haystack。海底捞针实验,从超长上下文寻找准确的关联信息。MoBA 和 NSA 两种方法都达到了 100%,差距可以说微乎其微,非常接近了。 关于两篇论文,我的感受论文的主要内容基本如上所述。我的感觉就是,高手过招,神仙打架,你中有我,我中有你,让我身在国内感受到了 AI 科技进步的点滴。论文写的简洁清晰,我之前看 GPT4的技术报告,洋洋洒洒将近100页,看得我眼睛疼。现在 MoBA 和 NSA 两篇论文,写作扎实,数据清晰,花不到一个小时就能看完,我给两篇论文竖起大拇指。我为国内有这种扎实做创新的团队鼓鼓掌!!!关于 NSA 的疑问最后我还是有点疑问:三种策略,各自对效果贡献多少?论文实验显示,attention 变的稀疏了,关注的信息少了,模型效果反而提升了,这似乎有点反直觉。换句话说,NSA 用了三种策略,每种策略各自起到了多大的作用?我没有从论文中看到。就像 MoBA 中所提,一个层级的 block 选择,其实可以涵盖好几种 sparse attention 策略,那么,不同策略如何衡量之间的差异呢?以上。—文章来源 JoiNLP



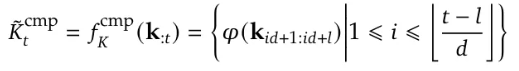
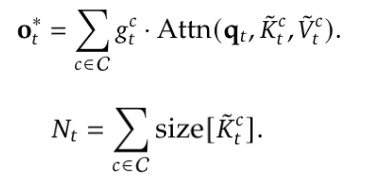









Comments NOTHING