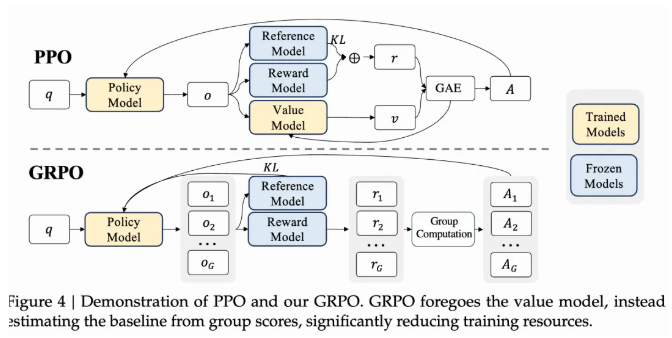
从Policy Gradient到REINFORCE++ 酥酥 发布于 2025-02-19 136 次阅读 强化学习的核心目标是通过不断调整策略(即根据当前状态选择动作的规则),使智能体表现得更好。在强化学习中,有几个关键元素至关重要:首先是奖励模型和价值函数,它们用于评估每个动作或策略的优劣,从而决定模型优化的方向;其次是更新规则,主要涉及损失函数的约束项,它决定了策略更新的力度和稳定性。 本文首先介绍了三类基础的强化学习算法,这三类算法主要在奖励计算和更新规则上有所不同,是 RLHF(人类反馈强化学习)的核心。接着,重点讨论了四种改进方法:REINFORCE、RLOO、PRIME 和 REINFORCE++,它们通过引入 EMA、在线采样、过程奖励等技术,使奖励更加无偏并提高密集成都。最后,介绍了 GRPO(Group Relative Policy Optimization)方法,它在奖励函数的计算和策略更新规则上做出了进一步的改进,以提升训练的稳定性和效率。 01 Policy Gradient最早的 Policy Gradient Methods 就是直接优化策略的一种方法。简单来说,策略梯度方法通过计算“策略梯度”(表示如何调整策略模型以提升表现)来更新策略,从而让智能体在长期内获得更高的奖励。 具体步骤是:1. 计算策略梯度:通过当前策略和动作的效果(优势函数),我们可以计算出一个梯度(action 对于 policy model 的梯度),告诉我们如何调整策略。 2. 优化策略:通过梯度上升的方法调整策略参数,以提升智能体的表现。 3. 反复更新:这个过程是一个反复的采样和优化过程,每次都会根据新的数据调整策略。 策略梯度的定义如下所示: 这是我们的目标函数,我们希望最大化这个目标。简而言之,就是通过调整策略参数 ,使得智能体选择的动作(那些优势高的动作)变得更加可能。对于 LLM,也就是直接将 outcome reward 作为每个 token 的 advantage。例如有两个 sample,分别为错误和正确,第一个 sample 有 5 个 token,它的 advantage 矩阵为 [0,0,0,0,0];第二个 sample 有 6 个 token,它的 advantage 矩阵为 [1,1,1,1,1,1],不断提升正确样本的 token 概率。 这里的问题在于,如果我们对同一批数据做多次优化,可能会导致策略的更新过大(比如参数调整过猛)。这样会使得策略发生剧烈变化,导致性能反而变差。因此,过度更新会导致学习不稳定。 02 TRPO (Trust Region Policy Optimization)TRPO(Trust Region Policy Optimization)是一种改进的策略优化方法,核心思想是限制策略更新的幅度,避免策略变化过大导致学习不稳定。简单来说,TRPO 通过引入“信赖区域”的概念,确保每次更新后的策略不会偏离旧策略太远,从而保证学习过程的平稳性。他的目标函数如下所示: 通过最大化这个目标函数,TRPO 试图找到一种策略,使得新策略在优势动作上的概率更高。同时,KL 散度用于衡量当前策略和旧策略之间的差异。这个约束确保了策略的更新不会过于激进。 当然直接求解这个问题是很困难的,TRPO 在其具体实现中做了一步近似操作来快速求解,作者对目标和约束进行了泰勒展开,并分别用一阶和二阶进行近似,最后得出的结果需要用到 hessian 矩阵 H 和 g(目标函数对 policy 的梯度)。 这对于 LLM 来说是不可接受的,因此作者又用了共轭梯度的方法避免存储 hessian 矩阵,总体优化比较复杂,而且因为 KL 散度和优化目标都是泰勒近似,很难保证 KL 散度的约束一定被满足。因此每一轮迭代 TRPO 还要通过先行搜索找到一个整数 i 来强行使得 KL diververge 的约束被满足。 这里就有一个有趣的问题,就是为什么选择把 KL 散度作为一个 hard constraint 而不是一个目标函数的惩罚项。 实际上原作者是证明了,这种形式的惩罚项会形成一个 lower bound 来限制策略的变化。但是作者认为如果使用惩罚项,𝛽 系数需要针对不同任务进行调整。在一个任务中,合适的 𝛽 值可能在学习的不同阶段有所不同。固定的 𝛽 值在某些情况下可能会导致策略更新过大或过小,从而影响训练效果。 03 PPO (Proximal Policy Optimization Algorithms)TRPO 算法在很多场景上的应用都很成功,但是我们也发现它的计算过程非常复杂,每一步更新的运算量非常大。于是,TRPO 算法的改进版——PPO 算法在 2017 年被提出,PPO 基于 TRPO 的思想,但是其算法实现更加简单。并且大量的实验结果表明,与 TRPO 相比,PPO 能学习得一样好(甚至更快),这使得 PPO 成为非常流行的强化学习算法。 从这里开始我们使用 LLM 的 notion 方便理解,即 q 作为 state(输入token),o 作为 action,输出 token,policy model 即 LLM 模型。传统的 PPO 由如下公式训练,直接将 KL divergence 的 term 替换成了 CLIP 的操作。 3.1 优势函数(Advantage Function) 3.2 值函数(Value Function)尽管蒙特卡洛估计(MC 估计)是无偏的,但它因为依赖所有未来的动作和奖励,而可能受到很高的方差影响。为了降低方差,引入了值函数,它预测从某个状态出发,智能体能够获得的累计奖励。值函数有助于在计算优势函数时减少波动。常见的方式是使用广义优势估计(GAE)来减少方差,同时保持估计的偏差在可接受范围内。GAE 公式如下: 04 在 LLM 应用中,奖励 r(x, y) 通常只在完整序列生成后获得。这种方法允许使用 REINFORCE 估计器来优化整个序列的奖励目标: 为了在保持无偏估计的同时减少方差,引入了一个基线 b: 一个简单有效的基线是训练过程中所有奖励的移动平均值: 05 RLOO (REINFORCE Leave-One-Out) REINFORCE Leave-One-Out (RLOO) 估计器利用多个样本来减少方差:每个样本的奖励可以作为其他样本的基线;策略更新通过对每个样本的梯度估计取平均来实现,从而得到一个方差减少的蒙特卡洛(MC)估计。 RLOO 估计器的定义如下: 06 PRIME6.1 稠密奖励信号的重要意义PPO 的方法可以自然地将稠密奖励融入到优势函数中,但在大多数LLM实践中比如 RLOO 和 Reinforce,实际可用的奖励模型(ORM)通常是输出奖励模型(Outcome Reward Models)。这意味着通常只有最后一个 token 才会得到有意义的奖励,而中间的 token不会获得奖励。 这种简化形式虽然更易实现,但奖励稀疏性问题会导致许多问题: 1. 错误过程的解决方案:奖励只出现在生成过程的最后,可能会导致策略学习出错的过程(如不正确的生成过程),但最终得到正确的答案。 2. 样本效率降低:由于奖励仅在最后提供,智能体需要较长的时间来感知并学习每个 token 对最终结果的影响,导致样本效率下降。 3. 信用分配问题(Credit Assignment Problem):这种奖励结构使得很难追溯每个 token 的贡献,尤其在生成过程中,智能体需要学习如何将奖励归因于先前的生成步骤。 这些问题在复杂任务中尤为突出,因为这些任务可能需要更多的思考和执行步骤,因此需要稠密奖励(即在每个 token 生成时提供反馈)。使用采用稠密奖励模型(PRM)来缓解奖励稀疏性问题是比较直观的,但是难以训练,而且成本较高。6.2 PRM-free的dense rewardPRIME 的核心思想是应用隐式过程奖励,这些奖励可以从隐式奖励模型(Implicit PRM)中推导出来,而这个模型只需要结果标签(outcome labels)来训练。推理阶段:在推理阶段,使用隐式奖励模型来计算每个 token 级的奖励,这里的 implicit reward 是和 ORM 的唯一区别,公式为: 6.3 优势估计因为现在我们可以为每个 token 提供 reward,那么就可以进一步考虑如何利用这些奖励估算优势,从而指导策略更新。PRIME 发现蒙特卡洛估计(MC)比广义优势估计(GAE)更简单,效果也更好,因此选择 MC 作为默认选择。对于每个生成的样本,优势函数通过 leave-one-out baseline 来估算进一步减小方差: 作者将 process reward 与 outcome reward 都利用了起来:隐式过程奖励的计算过程: 1. 使用平均的隐式过程奖励来计算留一法基准(LOO);2. 通过减去基准值来规范化每个步骤的过程奖励;3. 计算每个响应的折扣回报(discounted return);结果奖励(Outcome Rewards)则直接采用留一法(LOO),无需修改。而且结合得到最终的 reward: 训练算法采用传统的 PPO 策略。 07 REINFORCE++这里的核心贡献主要有两个:对 KL 散度的限制更加严格,以及优势函数逐 batch 做归一化,更加稳定。7.1 Token-Level KL惩罚在 REINFORCE++ 中,Token-Level KL 惩罚被整合到奖励函数中。奖励函数的定义如下: 这种做法有助于更好的 credit 分配,同时与过程奖励模型(PRM)无缝集成,增强了训练的稳定性。7.2 Advantage Normalization(优势标准化) 为了确保梯度的稳定性并避免训练中的发散,文章对优势进行 z-score 标准化: 08 GRPO GRPO 是 PPO 的又一改进,主要是想去掉 value model 的存在,同时克服奖励稀疏性的问题。GRPO 的目标函数如下: 通过以下方式解决了 PPO 的局限性: 1. 去除价值函数:GRPO 不需要额外的价值函数模型,而是使用多组采样输出的平均奖励作为基线(baseline)。 3. KL 正则化:相比于,REINFORCE++,GRPO 在损失函数中直接加入 KL 散度正则项,而不是将 KL 惩罚整合到奖励中,从而简化了优势函数的计算。 09 总结这篇文章总结了一些 RL 的重要工作,早起策略梯度方法(Policy Gradient)通过计算策略的梯度,优化策略,从而帮助智能体在长期内获得更高的奖励。为了改进 PPO(Proximal Policy Optimization)方法的计算复杂性和不稳定性,提出了多种改进算法,包括 TRPO、GRPO 和 REINFORCE 系列。 1. REINFORCE 通过计算整个序列的奖励,优化策略,适合用于LLM(大规模语言模型)训练,其中采用了优势函数(Advantage Function)来评价每个动作的优越性。该方法使用了无偏估计和基线来减少方差,提高训练稳定性。 2. REINFORCE Leave-One-Out (RLOO) 进一步减少了方差,通过多个样本的留一法(Leave-One-Out)计算基线,优化了奖励估计。它通过**多样本在线采样来生成方差减少的蒙特卡洛估计,从而提高了训练的效率。 3. GRPO(Group Relative Policy Optimization)通过避免使用额外的价值函数,改进了 PPO 的计算复杂性,并利用多个从旧策略中采样的输出的平均奖励作为基线,从而 t 提高了 reward 质量。 4. REINFORCE++ 通过 token 级 KL 惩罚和优势标准化,进一步稳定了训练过程。它通过规范化优势函数,减少了梯度的波动,并引入了更加严格的 KL 惩罚,进一步提高了策略更新的稳定性。未来展望1. 奖励模型的精确性:目前,LLM 训练中通常依赖于最终结果的奖励,而不是每个生成步骤的奖励。未来可以探索更精细的奖励模型,例如过程奖励,为每个推理步骤提供即时反馈,从而提高训练效率和稳定性。 2. 计算效率和扩展性:随着模型规模的不断增大,计算成本和内存消耗将成为主要瓶颈。未来需要进一步优化策略更新算法,减少计算复杂性和内存开销,例如通过改进近似 KL 散度的估计方法或探索新的正则化技术。 3. 多样本采样的优化:在 RLOO 和 GRPO 中,样本采样被用来减少方差并提高训练效果。未来的研究可以进一步优化采样策略,提高采样效率,减少训练时间,同时保持高效的策略更新。 4. 动态更新的奖励模型:随着策略的训练进展,旧的奖励模型可能无法有效地评估新的策略。未来可以探索动态更新奖励模型的方式,利用迭代强化学习来不断提升奖励模型的准确性,从而更好地引导策略优化。 总之,随着强化学习方法的不断发展,如何优化奖励模型、减少计算开销,并提升训练效率,仍然是未来研究的重要方向。 — 文章来源 PaperWeekly
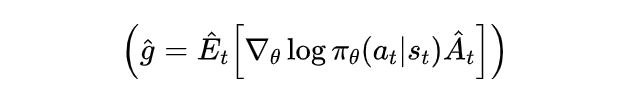

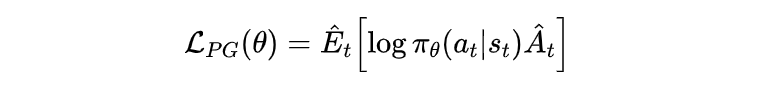
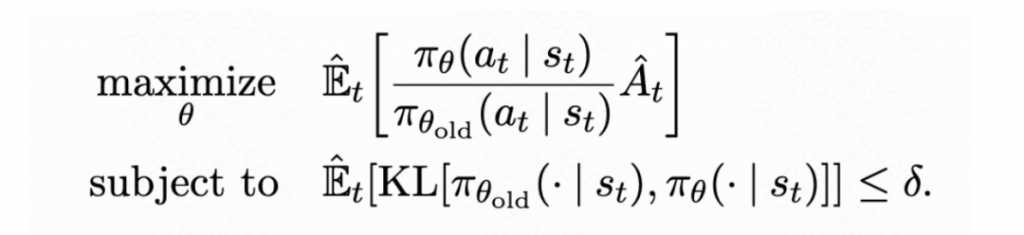
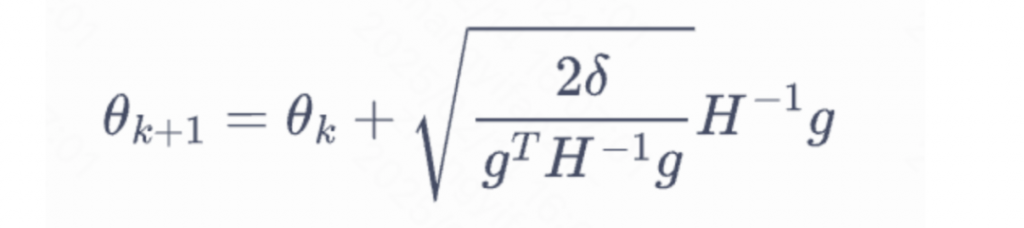
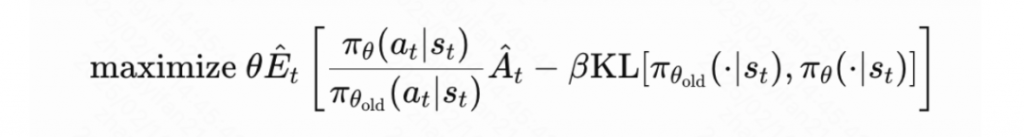
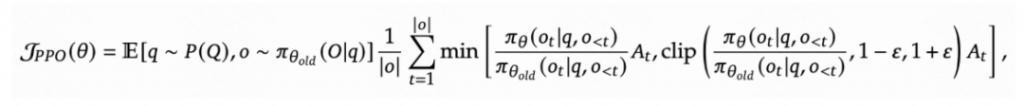

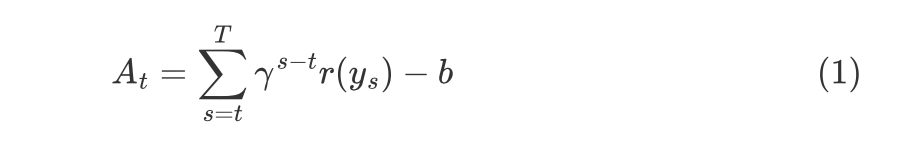

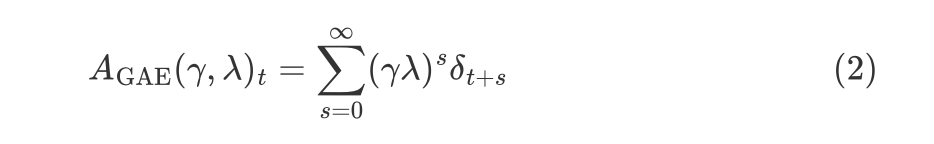

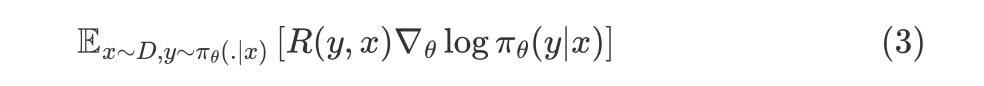
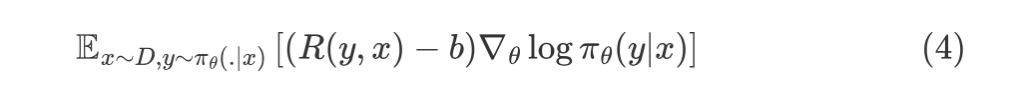
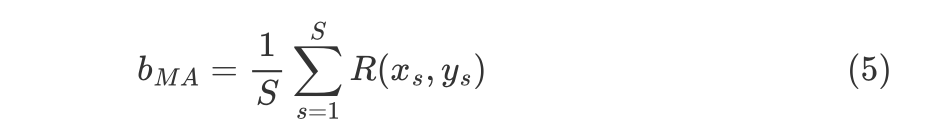

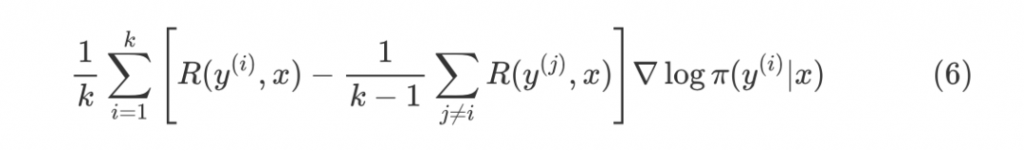


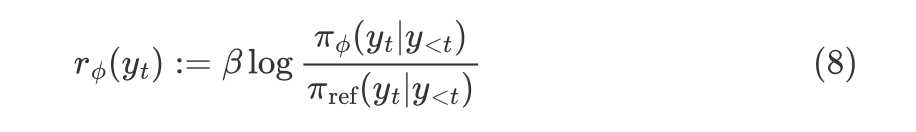



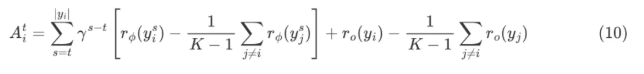
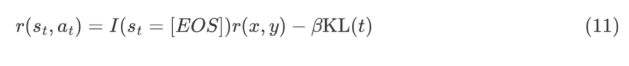

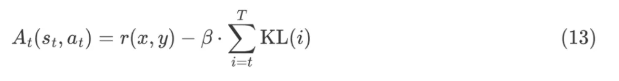












Comments NOTHING