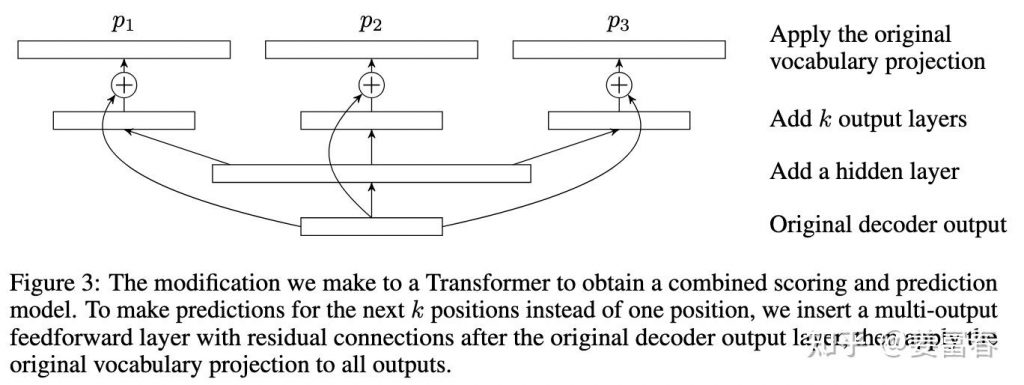
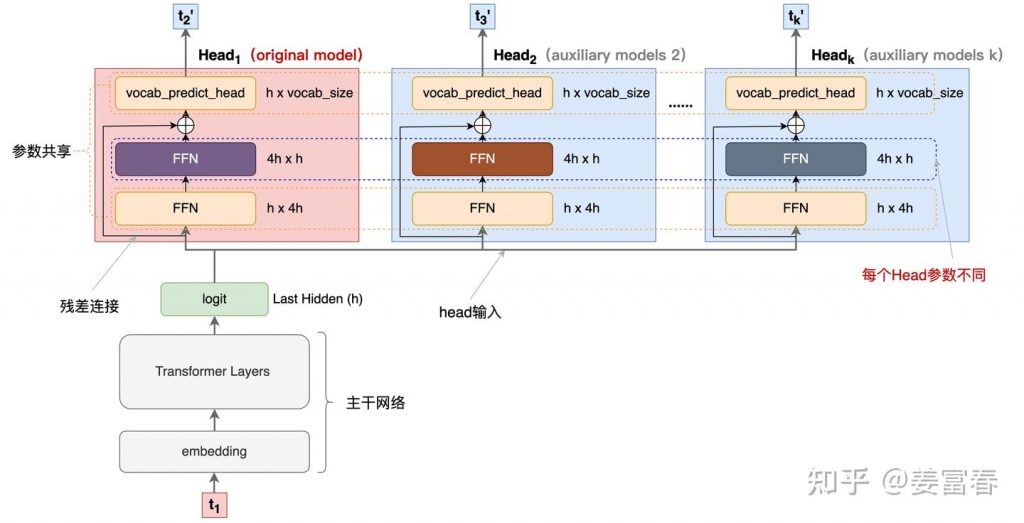
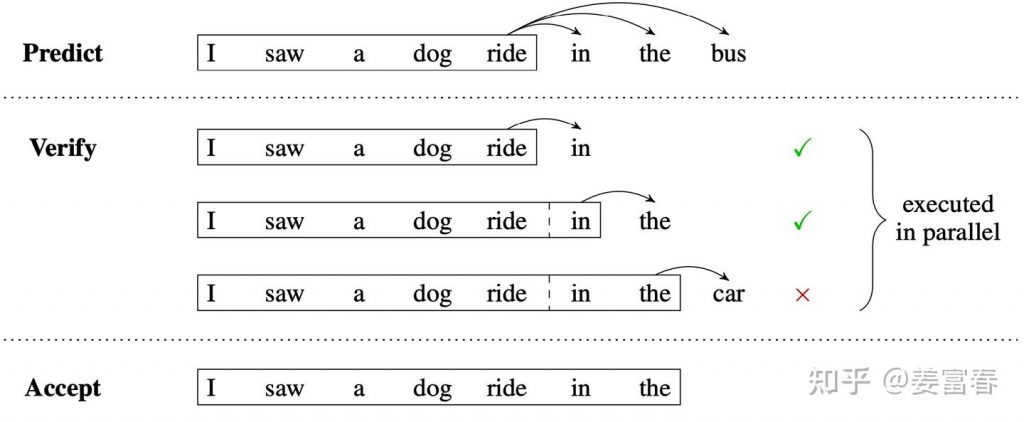
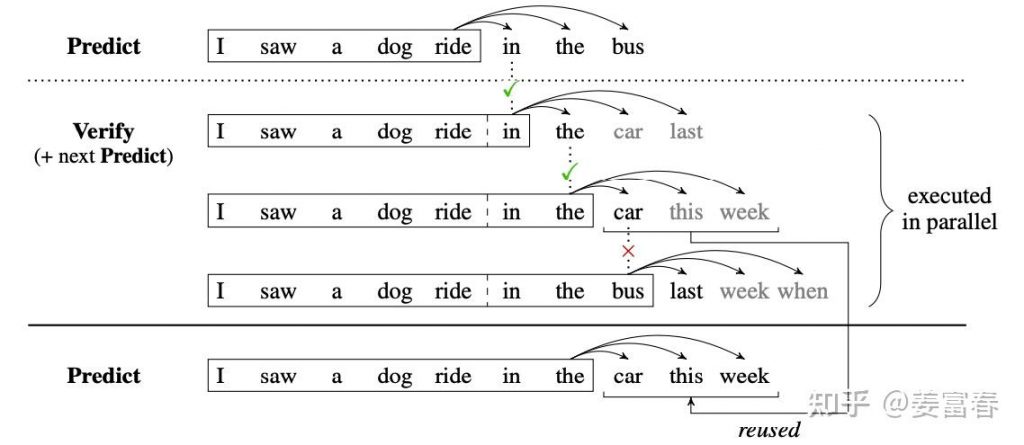
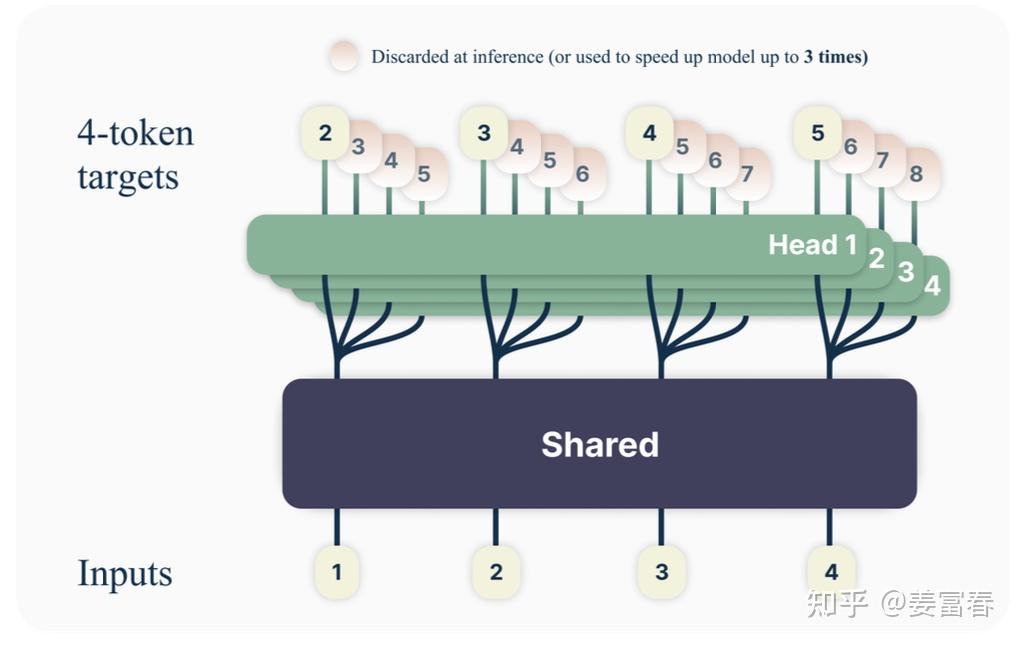
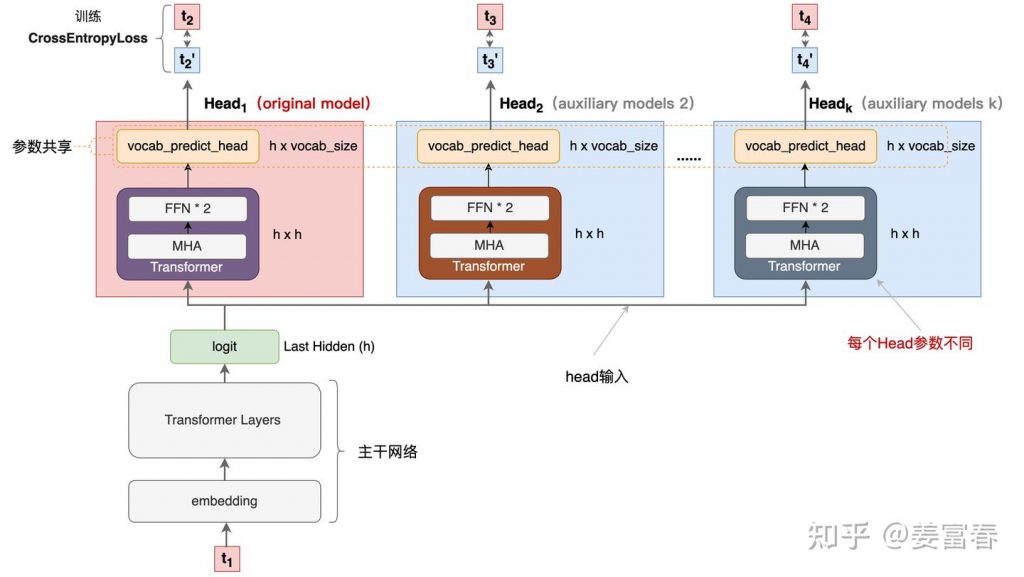
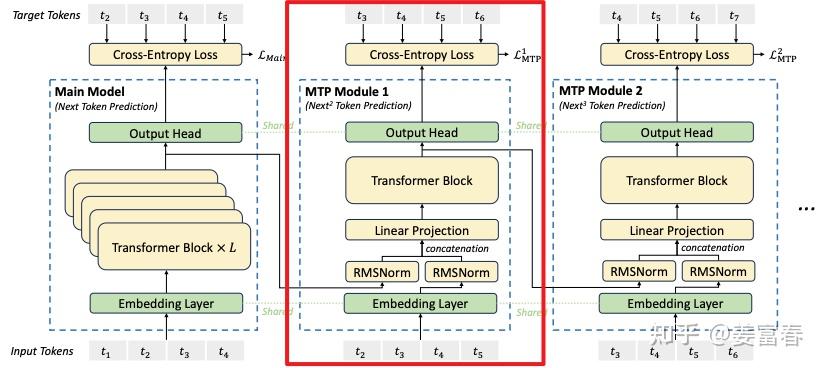
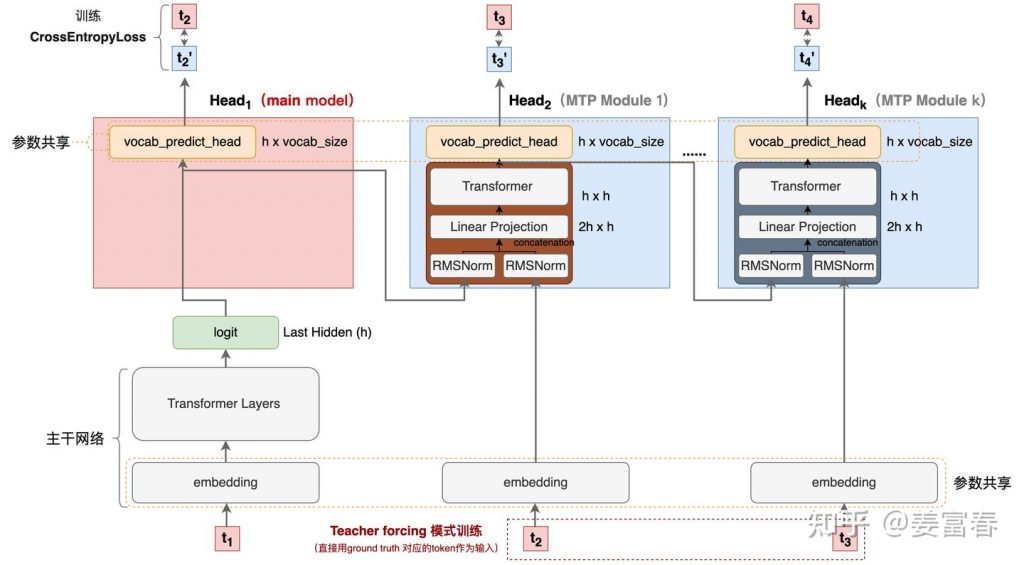
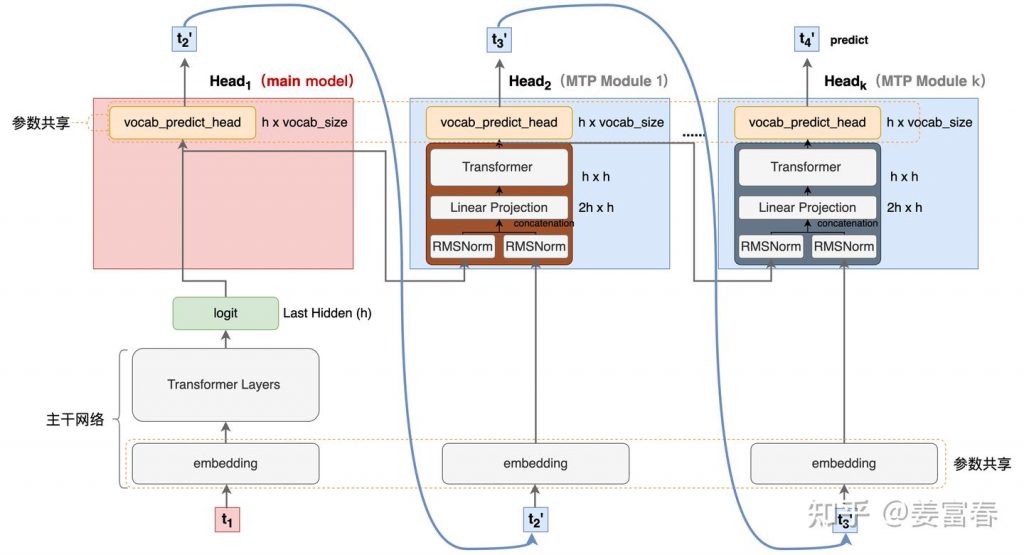
deepseek技术解读(2)-MTP(Multi-Token Prediction)的前世今生 酥酥 发布于 2025-02-15 105 次阅读 0.引言 最近整理deepseek的技术线,针对MTP(Multi-Token Prediction)方法做了些扩展的阅读和学习。主要参考3篇论文了解了MTP的前世今生。本文章结合业界的一些探索,并试图增加自己的一些理解来讲讲MTP方法。下面我们进入正题。 1.为什么要做MTP 在学习具体的方法前,我们首先了解下为什么要做MTP(Multi-Token Prediction)? 背景 我们都知道,当前主流的大模型(LLMs)都是decoder-base的模型结构,也就是无论在模型训练还是在推理阶段,对于一个序列的生成过程,都是token-by-token的。每次在生成一个token的时候,都要频繁跟访存交互,加载KV-Cache,再通过多层网络做完整的前向计算。对于这样的访存密集型的任务,通常会因为访存效率形成训练或推理的瓶颈。 针对token-by-token生成效率的瓶颈,业界很多方法来优化,包括减少存储的空间和减少访存次数等,进而提升训练和推理性能。 MTP方法的作用 本文要学习的MTP方法,也是优化训练和推理效率的一个分支系列。 核心思想:通过解码阶段的优化,将1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。具体来说,在训练阶段,一次生成多个后续token,可以一次学习多个位置的label,进而有效提升样本的利用效率,提升训练速度;在推理阶段通过一次生成多个token,实现成倍的推理加速来提升推理性能。 本文主要通过3篇paper把MTP业界探索的主线讲清楚;最后再详细讲解和对比下deepseek 的MTP方法。 2. MTP 方法的一些探索 2.1. Blockwise Parallel Decoding 首先我们来看一篇Google的工作,这是Google在18年发表在NIPS上的工作(18年是Transformer诞生的元年)。 paper:Blockwise Parallel Decoding for Deep Autoregressive Models 题外话:18年Transformer才刚出来,那时候模型只有BERT和GPT-1,模型的参数量也都只有0.1B左右,所以可以说MTP的研究并不是大模型时代的新物种,而是在第一代Transformer base的模型上,就有相应的研究了。 这是一篇重点研究推理阶段加速的方法,从论文标题『块并行解码』可以看出隐含在推理阶段不是token-by-token 生成的方式。我们先看下论文中的网络结构图(图1): 图1、Blockwise Parallel Decoding 网络框图 从上图能看到Blockwise Parallel Decoding网络是个并行计算的过程,但遗漏了很多文中表述的细节,也不像是在描述一个Transformer base的网络(这也可以理解,18年,还是SVM、LSTM统治的时代,确实不像现在,Transformer那时候不是个共识性的产物) 为了直观理解作者的方法,也更符合当前描述tranformer网络结构的方式,我按照自己的理解补充了一些细节,如图2所示: 图2、Blockwise Parallel Decoding 网络框图(yy版) 图3、Blockwise Parallel Decoding 推理 图4、Predict和Verify重叠设计 至此,我们完整描述了Blockwise Parallel Decoding 的核心内容,该方法主要是为了做推理阶段的并行加速而设计的。虽然命名上没有遵循MPT类,但后面一些演进的方法比如Speculative Sample和下面要介绍的Meta’s MTP等,都有该方法设计的影子。 接下来我们看第二篇代表性方法 2.2. Meta’s MTP 这是meta 于2024年4月发表的一篇工作。 paper : Better & Faster Large Language Models via Multi-token Prediction 首先简述该工作的motivation 传统方法的问题(预测下一个token): 训练阶段:token-by-token生成,是一种感知局部的训练方法,难以学习长距离的依赖关系。 推理阶段:逐个token生成,推理速度较慢 MTP方法(一次预测多个token): 训练阶段:通过预测多步token,迫使模型学到更长的token依赖关系,从而更好理解上下文,避免陷入局部决策的学习模式。同时一次预测多个token,可大大提高样本的利用效率,相当于一次预估可生成多个<predict, label>样本,来更新模型,有助于模型加速收敛。 推理阶段:并行预估多个token,可提升推理速度 方法实现 我们仔细对比下图2和图6,网络结构基本一致,有两个微小的不同: 图2是2层FFN, 图6是一个Transformer 图6 除了可按图2方法一样可做并行推理,本文也重点考虑模型加速训练的优化,在模型训练时,多个头都会并行计算loss时,提升样本利用效率和加速模型收敛。 至此,我们讲完了两篇paper的主要工作,方法比较直观,接下来,我们再来看看DeepSeek 的 MTP 3. DeepSeek MTP 首先我们还是从网络结构出发,看看DeepSeek的MTP的设计。如下图7所示,乍看上去也是多头,但结构略复杂。且论文中也强调,在实现上保留了序列推理的连接关系(causal chain),如图中,从一个Module链接到后继Module的箭头。 图7、Deepseek MTP实现 我们先结合Deepseek V3论文中的公式详细讲解下MTP的实现。 3.1. MTP模块细节实现 图8、MTP多头训练,样本构建示意图 3.2. MTP模型训练 图9、Deepseek MTP实现(yy版) 3.3. MTP模型推理 DeepSeek V3中强调,MTP的设计主要是为了训练过程能加速收敛,更充分的使用训练样本。所以针对推理阶段只是简单介绍了一段。这里也稍微展开讲下推理的过程。 DeepSeek V3推理可以有两种方法: 方法1:直接把MTP Model头全部删掉,模型变成了一个Predict Next Token的 Main Model。然后部署模型做推理,这个就跟正常LLM模型推理一样。没有什么加速效果 方法2:保留MTP Model 做self-speculative decoding,这样充分使用多Head预测能力,提升推理加速性能。类似2.1中介绍的三阶段 图10、Deepseek MTP推理阶段模型图 4. 总结 本文对DeepSeek-V3的MTP方法,做了些详细的扩展解读。从类似工作延续的角度和细节展开角度做了下整理。好多理解都是结合个人的知识做的一些解读,不一定正确。如有错误,欢迎指正~ 5. 参考文献 DeepSeek V3 Blockwise Parallel Decoding for Deep Autoregressive Models Better & Faster Large Language Models via Multi-token Prediction EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty — 文章来源 知乎 链接:https://zhuanlan.zhihu.com/p/18056041194





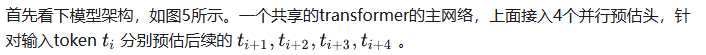















Comments NOTHING