






x86 处理器使用的三种浮点数二进制存储格式都是由 IEEE 标准 754-1985。二进制浮点数运算 (Standard 754-1985 for Binary Floating-Point Arithmetic) 所指定。
下表列出了它们的特点。
| 单精度 | 32 位:1 位符号位,8 位阶码,23 位为有效数字的小数部分。大致的规格化范围:2-126 〜2127 。也被称为短实数 (short real) |
| 双精度 | 64 位:1 位符号位,11 位阶码,52 位为有效数字的小数部分。大致的规格化范围:2-1022 〜21023 。也被称为长实数 (longreal) |
| 扩展双精度 | 80 位:1 位符号位,15 位阶码,1 位为整数部分,63 位为有效数字的小数部分。大致的规格化范围:2-16382〜216383。也被称为扩展实数 (extended real) |
由于三种格式比较相似,因此本节将重点关注单精度格式,如下图所示。32 位数值的最高有效位(MSB) 在最左边。标注为小数 (fraction) 的字段表示的是有效数字的小数部分。如同预想的一样,各个字节按照小端顺序(最低有效位 (LSB) 在起始地址上)存放在内存中。

1) 符号位
如果符号位为 1,则该数为负;如果符号位为 0,则该数为正。零被认为是正数。
2) 有效数字
在浮点数表达式 m*be 中,m 称为有效数字或尾数;b 为基数;e 为阶码。浮点数的有效数字(或尾数)由小数点左右的十进制数字构成。同样的概念也可以扩展到浮点数的小数部分。例如,十进制数 123.154 可以表示为下面的累加和形式:
123.154 = ( 1 X 102 ) + (2 X 101 ) + ( 3 X 100 ) + ( 1 X 10-1 ) + ( 5 X 10-6 )( 4 X 10-3 )
小数点左边数字的阶码都为正,右边数字的阶码都为负。
二进制浮点数也可以使用加权位计数法。浮点数十进制数值 11.1011 表示为:
11.1011 = (1 X 21 ) + (1 X 20 ) + (1 X 2-1 )( 0 X 2-2 ) + (1 X 2-3 ) + (1 X 2-4 )
小数点右边的数字还有一种表达方式,即将它们列为分数之和,其中分母为 2 的幂。上例的和为 11/16 ( 或 0.6875):
.1011 = 1/2+0/4+1/8+1/16=11/16
生成的小数部分非常直观。十进制分子 (11) 表示的就是二进制位组合 1011。如果小数点右边的有效位个数为 e 则十进制分母就为 2e :上例中,e=4,则有 2e=16。下表列出了更多的例子,来展示将二进制浮点数转换为以 10 为基数的分数。
| 二进制浮点数 | 基数为 10 的分数 | 二进制浮点数 | 基数为 10 的分数 |
|---|---|---|---|
| 11.11 | 3 3/4 | 0.00101 | 5/32 |
| 101.0011 | 5 3/16 | 1.011 | 1 3/8 |
| 1101.100101 | 13 37/64 | 0.00000000000000000000001 | 1/8388608 |
表中最后一项为 23 位规格化有效数字可以保存的最小分数。为便于参考,下表列出了二进制浮点数及其等价的十进制分数和十进制数值。
| 二进制 | 十进制分数 | 十进制数值 | 二进制 | 十进制分数 | 十进制数值 |
|---|---|---|---|---|---|
| .1 | 1/2 | .5 | .0001 | 1/16 | .0625 |
| .01 | 1/4 | .25 | .00001 | 1/32 | .03125 |
| .001 | 1/8 | .125 |
3) 有效数字的精度
用有限位数表示的任何浮点数格式都无法表示完整连续的实数。例如,假设一个简单的浮点数格式有 5 位有效数字,那么将无法表示范围在 1.1111〜10.000 之间的二进制数。比如,二进制数 1.11111 就需要更精确的有效数字。将这个思想扩展到 IEEE 双精度格式,就会发现其 53 位有效数字无法表示需要 54 位或更多位的二进制数值。
当十进制小数可以表示为形如 (1/2+1/4+1/8+…) 的分数之和时,发现与之对应的二进制实数就非常容易了。如下表所示,左列中的大多数分数不容易转换为二进制。不过,可以将它们写成第二列的形式。
| 十进制分数 | 分解为… | 二进制实数 | 十进制分数 | 分解为… | 二进制实数 |
|---|---|---|---|---|---|
| 1/2 | 1/2 | .1 | 3/8 | 1/4+1/8 | .011 |
| 1/4 | 1/4 | .01 | 1/16 | 1/16 | .0001 |
| 3/4 | 1/2+1/4 | .11 | 3/16 | 1/8+1/16 | .0011 |
| 1/8 | 1/8 | .001 | 5/16 | 1/4+1/16 | .0101 |
| 7/8 | 1/2+1/4+1/8 | .111 |
很多实数,如 1/10(0.1)或 1/100(0.01),不能表示为有限位的二进制数,它们只能近似地表示为一组以 2 的幂为分母的分数之和。想想看,像 $39.95 这样的货币值受到了怎样的影响!
使用二进制长除法
当十进制数比较小的时候,将十进制分数转换为二进制的一个简单方法就是:先将分子与分母转换为二进制,再执行长除。例如,十进制数 0.5 表示为分数就是 5/10,那么十进制 5 等于二进制 0101,十进制 10 等于二进制 1010。执行了长除之后,商为二进制数 0.1:

当被除数减去除数 1010 的结果为 0 时,除法完成。因此,十进制分数 5/10 等于二进制数 0.1。这种方法被称为二进制长除法(binary long division method)。
下面用二进制长除法将十进制数 0.2(2/10)转换为二进制数。首先,用二进制 10 除以二进制 1010(十进制 10):

第一个足够大到能上商的数是 10000。从 10000 减去 1010 后,余数为 110。添加一个 0 后,形成新的被除数 1100。从 1100 减去 1010 后,余数为 10。添加三个 0 后,形成新的被除数 10000。
这个数与第一个被除数相同。从这里开始,商的位序列出现重复(0011…),由此可知,不会得到确定的商,所以,0.2 也不能表示为有限位的数。其单精度编码的有效数字为 10011001100110011001100。
单精度数转换为十进制
IEEE 单精度数转换为十进制时,建议步骤如下:
1) 若 MSB 为 1,该数为负;否则,该数为正。
2) 其后 8 位为阶码。从中减去二进制值 01111111(十进制数 127),生成无偏差阶码。将无偏差阶码转换为十进制。
3) 其后 23 位表示有效数字。添加“1.”,后面紧跟有效数字位,尾随零可以忽略。用形成的有效数字、第一步得到的符号和第二步计算出来的阶码,就构成一个二进制浮点数。
4) 对第三步生成的二进制数进行非规格化。(按照阶码的值移动二进制小数点。如果阶码为正,则右移;如果阶码为负,则左移。)
5) 利用加权位计数法,从左到右,将二进制浮点数转换为 2 的幂之和,形成十进制数。
【示例】IEEE(0 10000010 01011000000000000000000)转换为十进制
1) 该数为正数。
2) 无偏差阶码的二进制值为 00000011,十进制值为 3。
3) 将符号、阶码和有效数字组合起来即得该二进制数为 +1.01011 x2³。
4) 非规格化二进制数为 +1010.11。
5) 则该数的十进制值为 +10 3/4,或 +10.75。
FPU 不使用通用寄存器 (EAX、EBX 等等)。反之,它有自己的一组寄存器,称为寄存器栈 (register stack)。数值从内存加载到寄存器栈,然后执行计算,再将堆栈数值保存到内存。
FPU 指令用后缀 (postfix) 形式计算算术表达式,这和惠普计算器的方法大致相同。比如,现有一个中缀表达式 (infix expression):(5*6)+4,其后缀表达式为:
5 6 * 4 +
中缀表达式 (A+B)*C 要用括号来覆盖默认的优先级规则(乘法在加法之前)。与之等效的后缀表达式则不需要括号:
A B + C *
表达式堆栈
在计算后缀表达式的过程中,用堆栈来保存中间结果。下图展示了计算后缀表达式 56*4- 所需的步骤。堆栈条目被标记为 ST(0) 和 ST(1),其中 ST(0) 表示堆栈指针通常所指位置。

中缀表达式转换为后缀表达式的常见方法在互联网以及计算机科学入门读物中都可以查阅到,此处不再赘述。下表给岀了一些等价表达式。
| 中缀 | 后缀 | 中缀 | 后缀 |
|---|---|---|---|
| A+B | AB+ | (A+B)*(C+D) | AB+CD+* |
| (A-B)/D | AB-D/ | ((A+B)/C)*(E—F) | AB+C/EF-* |
FPU 数据寄存器
FPU 有 8 个独立的、可寻址的 80 位数据寄存器 R0〜R7,如下图所示,这些寄存器合称为寄存器栈。FPU 状态字中名为 TOP 的一个 3 位字段给出了当前处于栈顶的寄存器编号。例如,在下图中,TOP 等于二进制数 011,这表示栈顶为 R3。在编写浮点指令时,这个位置也称为 ST(0)(或简写为 ST)。最后一个寄存器为 ST(7)。

如同所想的一样,入栈(push)操作(也称为加载)将 TOP 减 1,并把操作数复制到标识为 ST(0) 的寄存器中。如果在入栈之前,TOP 等于 0,那么 TOP 就回绕到寄存器 R7。
出栈(pop)操作(也称为保存)把 ST(0) 的数据复制到操作数,再将TOP加1。如果在出栈之前,TOP 等于 7,则 TOP 就回绕到寄存器 R0。
如果加载到堆栈的数值覆盖了寄存器栈内原有的数据,就会产生一个浮点异常(floating-point exception)。下图展示了数据 1.0 和 2.0 入栈后的堆栈情况。

尽管理解 FPU 如何用一组有限数量的寄存器实现堆栈很有意思,但这里只需关注 ST(n),其中 ST(0) 总是表示栈顶。从这里开始,引用栈寄存器时将使用 ST(0),ST(1),以此类推。指令操作数不能直接引用寄存器编号。
寄存器中浮点数使用的是 IEEE 10 字节扩展实数格式(也被称为临时实数(temporary real))。当 FPU 把算术运算结果存入内存时,它会把结果转换成如下格式之一:整数、长整
数、单精度(短实数)、双精度(长实数),或者压缩二进制编码的十进制数(BCD)。
专用寄存器
FPU 有 6 个专用(special-purpose)寄存器,如下图所示:

- 操作码寄存器:保存最后执行的非控制指令的操作码。
- 控制寄存器:执行运算时,控制精度以及 FPU 使用的舍入方法。还可以用这个寄存器来屏蔽(隐藏)单个浮点异常。
- 状态寄存器:包含栈顶指针、条件码和异常警告。
- 标识寄存器:指明 FPU 数据寄存器栈内每个寄存器的内容。其中,每个寄存器都用两位来表示该寄存器包含的是一个有效数、零、特殊数值 (NaN、无穷、非规格化,或不支持的格式 ),还是为空。
- 最后指令指针寄存器:保存指向最后执行的非控制指令的指针。
- 最后数据(操作数)指针寄存器:保存指向数据操作数的指针,如果存在,那么该数被最后执行的指令所使用。
操作系统使用这些专用寄存器在任务切换时保存状态信息。
每个程序都可能出错,而 FPU 就需要处理这些结果。因而,它要识别并检测 6 种类型的异常条件:
- 无效操作(#I)
- 除零(#Z)
- 非规格化操作数(#D)
- 数字上溢(#O)
- 数字下溢(#U)
- 模糊精度(#P)
前三个(#I、#Z 和 #D)在全部运算操作发生前进行检测,后三个(#O、#U 和 #P)则在操作发生后检测。
每种异常都有对应的标志位和屏蔽位。当检测到浮点异常时,处理器将与之匹配的标志位置 1。每个被处理器标记的异常都有两种可能的操作:
- 如果相应的屏蔽位置 1,那么处理器自动处理异常并继续执行程序。
- 如果相应的屏蔽位清 0,那么处理器将调用软件异常处理程序。
大多数程序普遍都可以接受处理器的屏蔽(自动)响应。如果应用程序需要特殊响应,那么可以使用自定义异常处理程序。一条指令能触发多个异常,因此处理器要持续保存自上一次异常清零后所发生的全部异常。完成一系列计算后,可以检测是否发生了异常。
浮点数指令集
FPU 指令集有些复杂,因此这里只对其功能进行概述,并用具体例子给出编译器通常会生成的代码。此外,大家还将看到如何通过改变舍入模式来控制 FPU。指令集包括如下基本指令类型:
- 数据传送
- 基本算术运算
- 比较
- 超越函数
- 常数加载(仅对专门预定义的常数)
- x87 FPU 控制
- x87 FPU 和 SIMD 状态管理
浮点指令名用字母 F 开头,以区别于 CPU 指令。指令助记符的第二个字母(通常为 B 或 I)指明如何解释内存操作数:B 表示 BCD 操作数,I 表示二进制整数操作数。
如果这两个字母都没有使用,则内存操作数将被认为是实数。比如,FBLD 操作对象为 BCD 数值, FILD 操作对象为整数,而 FLD 操作对象为实数。
操作数
浮点指令可以包含零操作数、单操作数和双操作数。如果是双操作数,那么其中一个必然为浮点寄存器。指令中没有立即操作数,但是某些预定义常数(如 0.0,π 和 log210)可以加载到堆栈。
通用寄存器 EAX、EBX、ECX 和 EDX 不能作为操作数。(唯一的例外是 FSTSW,它将 FPU 状态字保存在 AX 中。)不允许内存-内存操作。
整数操作数从内存(不是从 CPU 寄存器)加载到 FPU,并自动转换为浮点格式。同样,将浮点数保存到整数内存操作数时,该数值也会被自动截断或舍入为整数。
初始化(FINIT)
FINIT 指令对 FPU 进行初始化。将 FPU 控制字设置为 037Fh,即屏蔽(隐藏)了所有浮点异常;舍入模式设置为最近偶数,计算精度设置为 64 位。建议在程序开始时调用 FINIT, 这样就可以了解处理器的起始状态。
浮点数据类型
现在快速回顾一下 MASM 支持的浮点数据类型(QWORD、TBYTE、REAL4、REAL8 和 REAL10),如下表所示。
| 类型 | 用法 |
|---|---|
| QWORD | 64 位整数 |
| TBYTE | 80 位(10 字节)整数 |
| REAL4 | 32 位(4 字节)IEEE 短实数 |
| REAL8 | 64 位(8 字节)IEEE 长实数 |
| REAL10 | 80 位(10 字节)IEEE 扩展实数 |
在定义 FPU 指令 的内存操作数时,将会使用到这些类型。例如,加载一个浮点变量到 FPU 堆栈,这个变量可以定义为 REAL4,REAL8 或 REAL10:
.data
bigVal REAL10 1.212342342234234243E+864
.code
fld bigVal ;加载变量到堆栈
加载浮点数值(FLD)
FLD(加载浮点数值)指令将浮点操作数复制到 FPU 堆栈栈顶(称为 ST(0))。操作数可以是 32 位、64 位、80 位的内存操作数(REAL4、REAL8、REAL10)或另一个 FPU 寄存器:
FLD m32fp
FLD m64fp
FLD m80fp
FLD ST(i)
内存操作数类型 FLD 支持的内存操作数类型与 MOV 指令一样。示例如下:
.data
array REAL8 10 DUP (?)
.code
fid array ;直接寻址
fid [array+16 ] ;直接偏移
fid REAL8 PTR[esi] ;间接寻址
fid array[esi] ;变址寻址
fid array[esi*8] ;带比例因子的变址
fid array[esi*TYPE array] ;带比例因子的变址
fid REAL8 PTR[ebx+esi] ;基址-变址
fid array[ebx+esi] ;基址-变址-偏移量
fid array[ebx+esi*TYPE array] ;带比例因子的基址-变址-偏移量
【示例】下面的例子加载两个直接操作数到 FPU 堆栈:
.data
dblOne REAL8 234.56
dblTwo REAL8 10.1
.code
fid dblOne ; ST(0) = dblOne
fid dblTwo ; ST(0) = dblTwo, ST(1) = dblOne
每条指令执行后的堆栈情况如下图所示:

执行第二条 FLD 时,TOP 减 1,这使得之前标记为 ST(0) 的堆栈元素变为了 ST(1)。
FILD
FILD(加载整数)指令将 16 位、32 位或 64 位有符号整数源操作数转换为双精度浮点数,并加载到 ST(0)。源操作数符号保留。FILD 支持的内存操作数类型与 MOV 指令一致(间接、变址、基址-变址等)。
加载常数
下面的指令将特定常数加载到堆栈。这些指令没有操作数:
- FLD1 指令将 1.0 压入寄存器堆栈。
- FLDL2T 指令将 log210 压入寄存器堆栈。
- FLDL2E 指令将 log2e 压入寄存器堆栈。
- FLDPI 指令将 π 压入寄存器堆栈。
- FLDLG2 指令将 log102 压入寄存器堆栈。
- FLDLN2 指令将 loge2压入寄存器堆栈。
- FLDZ(加载零)指令将 0.0 压入 FPU 堆栈。
保存浮点数值(FST, FSTP)
FST(保存浮点数值)指令将浮点操作数从 FPU 栈顶复制到内存。FST 支持的内存操作数类型与 FLD 一致。操作数可以为 32 位、64 位、80 位内存操作数(REAL4、REAL8、 REAL10)或另一个 FPU 寄存器:
FST m32fp FST m80fp
FST m64fp FST ST(i)
FST 不是弹出堆栈。下面的指令将 ST(0) 保存到内存。假设 ST(0) 等于 10.1,ST(1) 等于 234.56:
fst dblThree ; 10.1
fst dblFour ; 10.1
直观地说,代码段期望 dblFour 等于 234.56。但是第一条 FST 指令把 10.1 留在 ST(0) 中。如果代码段的意图是把 ST(1) 复制到 dblFour,那么就要用 FSTP 指令。
FSTP
FSTP(保存浮点值并将其出栈)指令将 ST(0) 的值复制到内存并将 ST(0) 弹出堆栈。假设执行下述指令前 ST(0) 等于 10.1,ST(1) 等于 234.56:
fstp dblThree ; 10.1
fstp dblFour ; 234.56
指令执行后,这两个数值会从堆栈中逻辑移除。从物理上看,每次执行 FSTP,TOP 指针都会减 1,修改 ST(0) 的位置。
FIST(保存整数)指令将 ST(0) 的值转换为有符号整数,并把结果保存到目标操作数。保存的值可以为字或双字。FIST 支持的内存操作数类型与 FST 一致。
下表列出了基本算术运算操作。所有算术运算指令支持的内存操作数类型与 FLD (加载)和 FST(保存)一致,因此,操作数可以是间接操作数、变址操作数和基址-变址操作数等等。
| FCHS | 修改符号 |
| FADD | 源操作数与目的操作数相加 |
| FSUB | 从目的操作数中减去源操作数 |
| FSUBR | 从源操作数中减去目的操作数 |
| FMUL | 源操作数与目的操作数相乘 |
| FDIV | 目的操作数除以源操作数 |
| FDIVR | 源操作数除以目的操作数 |
FCHS 和 FABS
FCHS( 修改符号 ) 指令将 ST(0) 中浮点数值的符号取反。FABS ( 绝对值 ) 指令清除 ST(0) 中数值的符号,以得到它的绝对值。这两条指令都没有操作数:
FCHS
FABS
FADD、FADDP、FIADD
FADD(加法)指令格式如下,其中,m32fp 是 REAL4 内存操作数,m64fp 即是 REAL8 内存操作数,i 是寄存器编号:
FADD
FADD m32fp
FADD m64fp
FADD ST(0), ST(i)
FADD ST(i) , ST(0)
无操作数
如果 FADD 没有操作数,则 ST(0)与 ST(1)相加,结果暂存在 ST(l)。然后 ST(0) 弹出堆栈,把加法结果保留在栈顶。假设堆栈已经包含了两个数值,下图展示了 FADD 的操作:

寄存器操作数
从同样的栈开始,如下所示将 ST(0) 加到 ST(1):

内存操作数
如果使用的是内存操作数,FADD 将操作数与 ST(0) 相加。示例如下:
fadd mySingle ; ST(0) += mySingle
fadd REAL8 PTR[esi] ; ST(0) += [esi]
FADDP
FADDP(相加并出栈)指令先执行加法操作,再将 ST(0) 弹出堆栈。MASM 支持如下格式:
FADDP ST(i),ST(0)
下图演示了 FADDP 的操作过程:

FIADD
FIADD(整数加法)指令先将源操作数转换为扩展双精度浮点数,再与 ST(0) 相加。指令语法如下:
FIADD ml6int
FIADD m32int
示例:
.data
myInteger DWORD 1
.code
fiadd myInteger ; ST(0) += myInteger
FSUB、FSUBP、FISUB
FSUB 指令从目的操作数中减去源操作数,并把结果保存在目的操作数中。目的操作数总是一个 FPU 寄存器,源操作数可以是 FPU 寄存器或者内存操作数。该指令操作数类型与 FADD 指令一致:
FSUB
FSUB m32fp
FSUB m64fp
FSUB ST(0), ST(i)
FSUB ST(i), ST(0)
FSUB 的操作与 FADD 相似,只不过它进行的是减法而不是加法。比如,无参数 FSUB 实现 ST(1) – ST(0),结果暂存于 ST(1)。然后 ST(0) 弹出堆栈,将减法结果留在栈顶。若 FSUB 使用内存操作数,则从 ST(0) 中减去内存操作数,且不再弹出堆栈。
fsub mySingle ; ST(0) -= mySingle
fsub array[edi*8] ; ST(0) -= array[edi*8]
FSUBP
FSUBP(相减并出栈)指令先执行减法,再将 ST(0) 弹出堆栈。MASM 支持如下格式:
FSUBP ST(i),ST(0)
FISUB
FISUB(整数减法)指令先把源操作数转换为扩展双精度浮点数,再从 ST(0) 中减去该操作数:
FISUB m16int
FISUB m32int
FMUL、FMULP、FIMUL
FMUL 指令将源操作数与目的操作数相乘,乘积保存在目的操作数中。目的操作数总是一个 FPU 寄存器,源操作数可以为寄存器或者内存操作数。其语法与 FADD 和 FSUB 相同:
FMUL
FMUL m32fp
FMUL m64fp
FMUL ST(0), ST(i)
FMUL ST(i), ST(0)
除了执行的是乘法而不是加法外,FMUL 的操作与 FADD 相同。比如,无参数 FMUL 将 ST(O) 与 ST(1) 相乘,乘积暂存于 ST(1)。然后 ST(0) 弹出堆栈,将乘积留在栈顶。同样,使用内存操作数的 FMUL 则将内存操作数与 ST(0) 相乘:
fmul mySingle ; ST(0) *= mySingle
FMULP
FMULP(相乘并出栈)指令先执行乘法,再将 ST(0) 弹出堆栈。MASM 支持如下格式:
FMULP ST(i),ST(O)
FIMUL 与 FIADD 相同,只是它执行的是乘法而不是加法:
FIMUL ml6int
FIMUL m32int
FDIV、FDIVP、FIDIV
FDIV 指令执行目的操作数除以源操作数,被除数保存在目的操作数中。目的操作数总是一个寄存器,源操作数可以为寄存器或者内存操作数。其语法与 FADD 和 FSUB 相同:
FDIV
FDIV m32fp
FDIV m64fp
FDIV ST(O), ST(i)
FDIV ST(i), ST(O)
除了执行的是除法而不是加法外,FDIV 的操作与 FADD 相同。比如,无参数 FDIV 执行 ST(1) 除以 ST(0)。然后 ST(0) 弹出堆栈,将被除数留在栈顶。使用内存操作数的 FDIV 将 ST(0) 除以内存操作数。下面的代码将 dblOne 除以 dblTwo,并将商保存到 dblQuot:
.data
dblOne REAL8 1234.56
dblTwo REAL8 10.0
dblQuot REAL8 ?
.code
fid dblOne ; 加载到 ST (0)
fdiv dblTwo ; ST(0) 除以 dblTwo
fstp dblQuot ; 将 ST(0) 保存到 dblQuot
若源操作数为 0,则产生除零异常。若源操作数等于正、负无穷,零或 NaN,则使用一些特殊情况。
FIDIV
FIDIV 指令先将整数源操作数转换为扩展双精度浮点数,再执行与 ST(0) 的除法。其语法如下:
FIDIV ml6int
FIDIV m32int
示例输入/输出(用户输入显示为粗体)如下:

若要完全理解汇编语言操作码和操作数,就需要花些时间了解汇编指令翻译成机器语言的方法。由于 Intel 指令集使用了丰富多样的指令和寻址模式,因此这个问题相当复杂。
Intel 8086 处理器是第一个使用复杂指令集计算机(Complex Instruction Set Computer, CISC)设计的处理器。这种指令集中包含了各种各样的内存寻址、移位、算术运算、数据传送和逻辑操作。
与 RISC(精简指令集计算机,Reduced Instruction Set Computer)指令相比,Intel 指令在编码和解码方面有些复杂。
指令编码(encode)是指将汇编语言指令及其操作数转换为机器码。指令解码(decode)是指将机器指令转换为汇编语言。对 Intel 指令编码和解码的逐步解释至少将有助于唤起对 MASM 作者们辛苦工作的理解和欣赏。
指令格式
一般的 x86 机器指令格式,如下图所示。包含了一个指令前缀字节、操作码、Mod R/M 字节、伸缩索引字节(SIB)、地址位移和立即数。
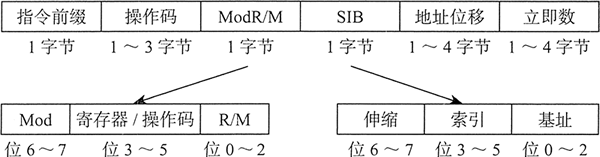
指令按小端顺序存放,因此前缀字节位于指令的起始地址。每条指令都有一个操作码,而其他字段则是可选的。少数指令包含了全部字段,平均来看,绝大多数指令都有 2 个或 3 个字节。
下面是对指令字段的简介:
1) 指令前缀覆盖默认操作数大小。
2) 操作码(操作代码)指定指令的特定变体。比如,按照使用的参数类型,指令 ADD 有 9 种不同的操作码。
3) Mod R/M 字段指定寻址模式和操作数。符号 “R/M” 代表的是寄存器和模式。下表列出了 Mod 字段。
| Mod | 位移 |
|---|---|
| 00 | DISP=0,位移低半部分和高半部分都无定义(除非r/m = 110) |
| 01 | DISP= 位移低半部分符号扩展到 16 位,位移高半部分无定义 |
| 10 | DISP= 位移高半部分和低半部分都有效 |
| 11 | R/M 字段包含的是寄存器编号 |
下表给出了当 Mod=10b 时 16 位应用程序的 R/M 字段。
| R/M | 有效地址 | R/M | 有效地址 |
|---|---|---|---|
| 000 | [BX+SIJ+D16 | 100 | [SI]+D16 |
| 001 | [BX+DI]+D16 | 101 | [DI]+D16 |
| 010 | [BP+SI]+D16 | 110 | [BP]+D16 |
| 011 | [BP+DIJ+D16 | 111 | [BX]+D16 |
4) 伸缩索引字节(scale index byte, SIB)用于计算数组索引偏移量。
5) 地址位移字段保存了操作数的偏移量,在基址-偏移量或基址-变址-偏移量寻址模式中,该字段还可以与基址或变址寄存器相加。
6) 立即数字段保存了常量操作数。

Comments NOTHING